** 코드의 경우 깃허브를 통해 동일한 내용을 더 깔끔하게 확인할 수 있습니다 : https://github.com/int29/PMLP-101
<실용적 머신러닝 시리즈 목차>
들어가며 : 들어가며(Introduction)
<챕터01 : 머신러닝 이해하기>
01화 : 머신러닝 이해하기(Understanding the Machine-Learning)
<챕터02 : 지도학습 알고리즘-분류>
02화 : 최근접이웃 알고리즘(K.N.N) (작성중)
03화 : 의사결정나무 알고리즘(Decision Tree) (작성중)
04화 : 부스팅트리 알고리즘(Boosting Tree) (작성중)
05화 : 앙상블트리 알고리즘(Ensemble Tree) (작성중)
06화 : 최신 트리 알고리즘(XGBoost, LightGBM, CatBoost) (작성중)
07화 : 나이브 베이즈 알고리즘(Naive Bayes) (작성중)
08화 : 서포트 백터 머신 알고리즘(SVM) (작성중)
09화 : 로지스틱회귀 알고리즘(Logistic Regression) (작성중)
<챕터03 : 지도학습 알고리즘-회귀>
10화 : 분류 알고리즘의 회귀 (Regression) (작성중)
11화 : 정규화 회귀 알고리즘(Regulated Regression) (작성중)
<챕터04 : 비지도학습 알고리즘>
12화 : 군집 알고리즘(Clustering) (작성중)
13화 : Representative Learning(PCA, TSNE) (작성중)
이번 장에서는 머신러닝이 무엇인지 정의로 부터 시작하여, 전체적인 머신러닝 프로세스에 대한 설명을 다룬다.
1. 머신러닝이란 무엇인가?
머신러닝이 2010년대 초반 시작한 빅데이터 신드롬에의해 대중에 유명해졌다보니, 머신러닝이 빅데이터와 함께 등장한 따끈 따끈한 최신 방법론이고, 개발에 특화된 부분이라 오해를 하곤한다. 하지만 기대와는 달리 적어도 60년 이상된 학문이고 개발 지식 뿐만 아니라 수학이나 통계적 지식이 필요하다.
머신러닝은 1959년 아서사무엘이 정의한 부분과 같이 명시적인 프로그래밍(explicitly programmed) 없이 컴퓨터에게 학습하는 능력을 부여 하는 것을 (gives computers the ability to learn) 연구하는 AI의 한분야를 말한다. [1]
쉽게 말해 머신러닝 알고리즘은 데이터로부터 배울 수 있는 능력을 개발하는 알고리즘이다. [2]
머신러닝 문제해결 패러다임
머신러닝 방식은 개발자 본인의 판단이 아닌 AI에게 판단을 맡기는 방식이라 할 수 있다. 아래 간단한 예시를 통해 기존 패러다임과 어떻게 다른지 살펴보자
사과와 수박을 구분하는 프로그램을 만든다고 해보자. 어떻게 만들것인가?
가장 일반적인 방법은 길이, 색깔, 크기 등 사과와 수박의 차이를 프로그래머 본인이 생각해보고 이를 코드로 구현하는 방법일 것이다. 핵심은 모델이 잘 작동하는지 여부가 아니라, 프로그래머 본인이 생각한 사과와 수박의 차이를 코드로 옮겨 개발한 다는 것이다.
이에 반해 머신러닝은 개발자가 사과와 수박의 차이를 정의하고 개발하는데 관심이 없다.1 프로그래머는 컴퓨터가 두 개의 차이를 잘 파악하고 구분할 수 있도록 하는 능력을 개발하는데 집중한다.

머신러닝은 학습하고 판단하는 능력을 개발하는 프로그래밍 패러다임이다.
더 복잡한 상황을 살펴보자, 우리가 스팸메일을 탐지하는 기능을 개발하는 개발자라면, 가장 쉽게 생각할 수 있는 방법인 스팸메일에 많이 등장하는 단어로 탐지모형 개발을 시도해볼 것이다.
확인 결과 무료 혜택 라는 단어가 가장 많았고 무료 혜택 이 등장하면 스팸으로 처리하는 모형을 릴리즈한다. 당연히 일반메일에도 무료 혜택 이라는 단어는 들어갈 것이고 더 정교한 로직을 개발하기 위해서 계속 수정을 진행할 것이다.

이러한 방식의 큰 문제는 시간이 흐를수록 수많은 수정으로 로직이 복잡해 질것이고,구분이 어려운 피싱메일부터 “무료 ㅎn ㅌn” 과 같이 스팸또한 빠르게 정교해진다는것이다. 더 근본적인 문제는 모든 스팸메일을 개발자가 직접 파악하기란 거의 불가능한 일이다.
머신러닝 방식으로 개발할 경우 개발자는 스팸메일 속에서 스팸메일이 일반메일과 다른점을 보이는 패턴을 스스로 찾아낼 수 있는 머신러닝 알고리즘을 개발하는데 집중한다.
이 과정에서 사람이 인지하지 못하는 미묘한 맥락을 오히려 모델이 발견할 수도 있고, 새로운 스팸패턴이 등장해도 이를 개발자가 추가하는 것이 아니라 머신러닝 알고리즘이 데이터속에 자동으로 스팸메일 패턴을 업데이트 한다.2

3. 머신러닝의 학습이란 무엇인가?
머신러닝은 데이터로부터 학습할 수 있는 능력을 개발하는 AI의 한 분야라면, 학습할 수 있는 능력이란 무엇일까?
Mitchell(1997)이 정의한 학습 알고리즘에 대한 정의를 살펴보자.
“학습알고리즘이란 특정 테스크($T$) 에 관해 경험($E$) 으로부터 학습하고, 성능($P$)을 측정하여 다시 경험($E$)을 활용하여 향상시키는 컴퓨터 프로그래밍을 학습(Learning Algorithms)이라 한다.” [3]
다소 어려운 정의이지만 중요한 정의이기 때문에 풀어서이해해보자.
머신러닝에게 학습이란? : 데이터의 패턴을 추상화하고 일반화하고 개선하는 과정
머신러닝은 컴퓨터가 학습하고 판단하는 능력을 갖도록 하는 AI의 한 분야이기 때문에 필연적으로 사람이 학습하는 방법에서 근본적인 아이디어를 차용했다 머신러닝에서의 학습은 사람이 경험을 통해 어떤 것을 배우고 개선하는것과 동일하게 데이터를 통해 학습하고 개선한다.
사람들은 스팸이라는 한가지 단어에 대해서도 맛있다,건강에 좋지 않다 같이 각기 다른 인식을 갖고있다. 이는 사람마다 스팸에 대한 다른 경험을 겪고 이 경험속에서 특징을 추출해 스팸=맛있다같은 인식을 형성하기 때문이다. 이러한 과정을 추상화라 부르는데, 추상화 란 개별적 사례들로부터 일반적 개념이나 원리를 형성하는 사고과정으로 일련의 관찰을 요약하여 새로운 것을 설명하거나 예측하고, 지식을 생성하는 것을 말한다. 사람들은 경험을 통해 추상화 과정을 거쳐 인식을 형성한다.
머신러닝 또한 마찬가지이다.$_{3}$
데이터(경험)에서 패턴을 추출하는 추상화와 학습하지 않은 데이터에도 잘 작동할 수 있도록 하는 일반화의 과정을 통해 데이터가 본래 갖고 있는 패턴인 모델 $f(x) $를 근사시킨 $\hat f(x)$ 를 추정하한다. 이러한 모델링과정을 학습(훈련)이라 한다.
모형(Model)에 대한 정의는 다양하지만 공통적으로 어떤 현상(혹은 실세계)을 표현, 설명 하는것을 말하는데, 만약 수학적으로 실세계나 현상을 표현한다면 수학적 모형이 되는것이다.[4]

안타깝게도 사람은 경험에 맞는 모형을 스스로 만들어 학습할 수 있지만, 머신러닝은 아직 경험속에서 적합한 모형과 학습 알고리즘을 스스로 선택하고 완성하지 못하기 때문에, 보통은 어떤 알고리즘이나 모형을 사용할지 선택해주어야 한다.
예를 들어 우리가 아래와 같은 일조량과 부동산 가격 데이터를 통해 일조량에 따른 부동산 가격 예측 머신러닝 모델을 개발한다고 해보자.
사람이 보기에는 일조량과 부동산 가격간의 선형 상관관계가 있기 때문에 선형회귀 방정식으로 표현이 가능할 것이라는 것을 유추할 수 있지만, 머신은 이 작업이 아직 불가능하기 때문에 $f(x)=ax+b$ 라는 선형 모형을 엔지니어가 선택해주게 된다. (여기서 $a$ 와 $b$ 를 파라미터라고 부른다.)

다만, 직선이라는 모형을 엔지니어가 정해줬을 뿐 모형의 구체적 형태나 성질(파라미터)은 모르기 때문에 모형은 아래와 같이 다양한 모습을 취할 수 있는 불확실한 상황을 보인다.
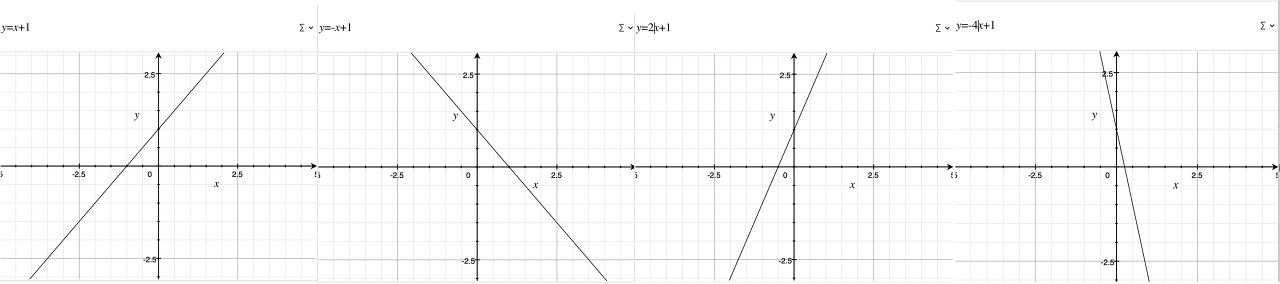
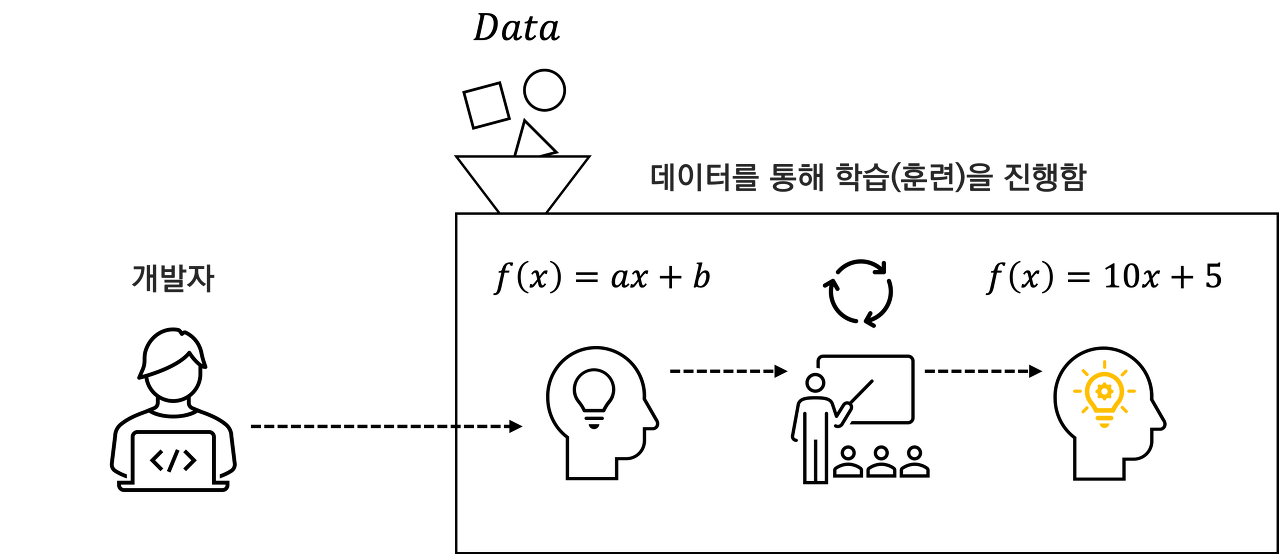
훈련데이터를 통한 학습을 진행할 경우 비로소 머신은 데이터의 특징을 추상하고 학습에 사용하지 않은 새로운 데이터에 대한 예측을 잘 진행할 수 있도록 일반화하여 적합한 선형 모형의 파라미터인 $a$ 와 $b$ 를 추정하여 $\hat f(x)$ 모델을 완성하여 학습을 완료한다.
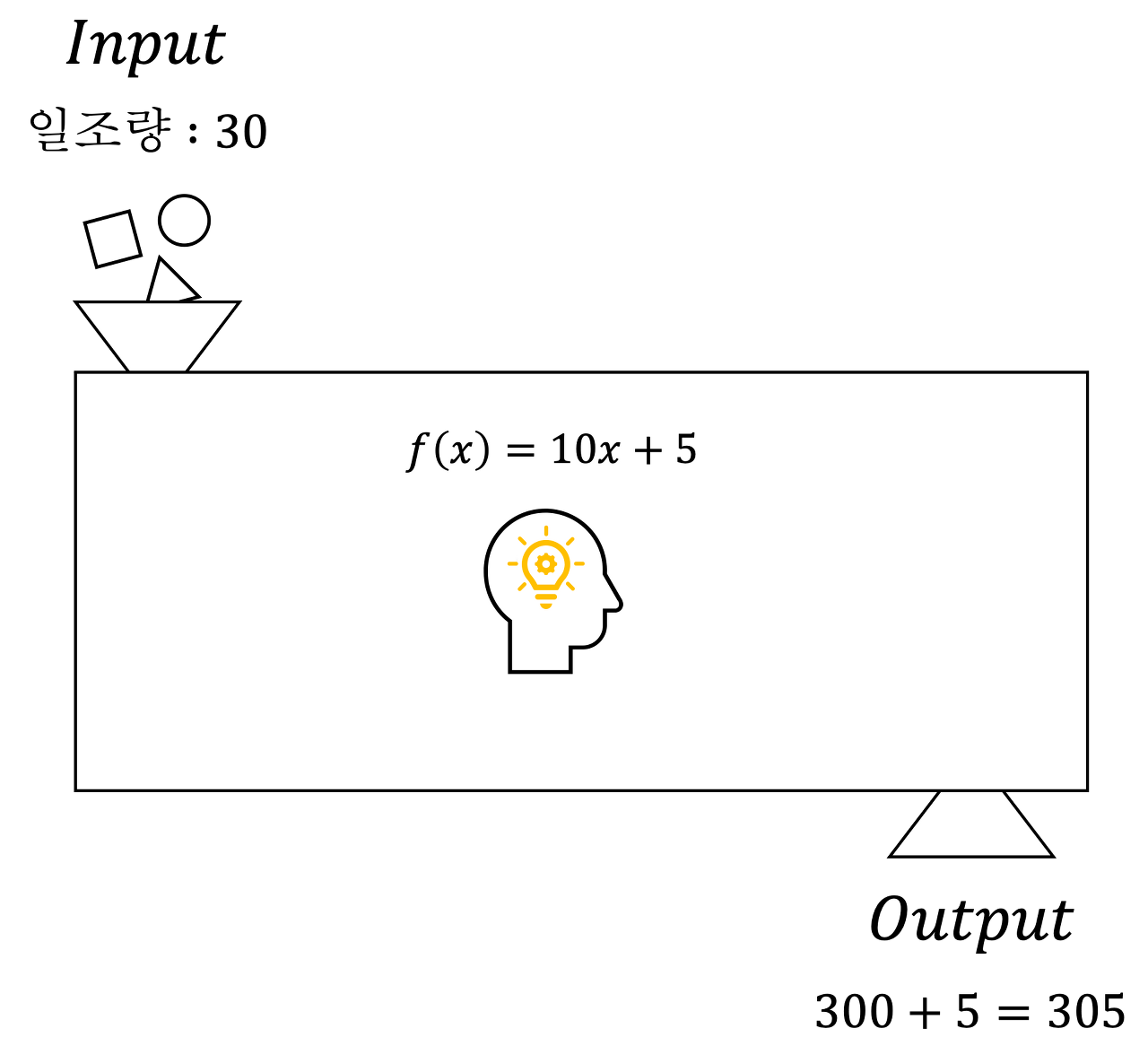
이렇게 데이터 속에서 학습을 통해 일조량과 집값간의 관계를 $\hat f(x)=10x+5$ 로 학습을 완료하였다면, 이후 어떤 일조량이 입력되더라도 추정한 $\hat f(x)$ 를 통해 $\hat y$ 라는 예측 결과를 계산한다.
모든 머신러닝 모형이 추상화과정, 위 정의한 학습과정을 갖는것은 아니다. 대표적으로 KNN(최근접 이웃 모형) 메모리상에 전체 데이터(관측치)에 대해 저장 했다가, 예측할 값이 들어오면 사전에 저장한 데이터와 비교하여 판단한다. 따라서 추상화-일반화 과정이 존재하지 않는데. 이러한 모형을 인스턴스기반 모형 (Instance Base Model) 이라 부른다. 이처럼 엄밀한 학문적 정의라기 보다, 대부분의 모형에 통용되는 나이브한 정의로 받아들였으면 좋겠다.
또한 위 회귀모형(Linear Regression)의 예시는 Prametric Model의 예시로 의사결정나무(Decision Tree)같은 Non-parametric Model의 경우 추상화한 결과가 파라미터로 정해지는 것은아니니, 추상화와 일반화의 과정을 거쳐서 데이터의 패턴을 갖는 모형을 만드는 것이지, "추상화+일반화=최적 파라미터" 라는 식으로 생각하지 않도록 주의해야한다.
4. 머신러닝의 타입
다시 아래 정의를 환기해보자
“학습알고리즘이란 특정 테스크($T$) 에 관해 경험($E$) 으로부터 학습하고, 성능($P$)을 측정하여 다시 경험($E$)을 활용하여 향상시키는 컴퓨터 프로그래밍을 학습(Learning Algorithms)이라 한다.” [3]
사람도 학습법과 해결하려는 문제가 여러가지인 것 처럼, 머신러닝은 학습하는 데이터 ($E$) 와 및 해결하려는 테스크( $T$ , Task)에 따라 지도학습과 비지도학습이라는 큰 틀로 나눌 수 있다.
지도학습
지도학습은 어떤 값을 예측하는 테스크($T$)를 해결하기 위해 예측하고자 하는 정답이 포함된 데이터($E$)로 학습시키는 학습 방법을 말한다. 정답이 존재하는 데이터를 통해 머신을 학습시키기 때문에 머신은 데이터와 타겟간의 관계를 학습하여 정답을 모르는 데이터가 들어오더라도 학습한 관계를 바탕으로 예측값을 반환한다. 수학 문제집의 정답이 있는 예제로 학습하고 정답이 없는 연습문제를 푸는방법과 동일하다. 앞서 살펴봤던 일조량 통해 부동산가격을 예측하는 모형은 부동산가격을 예측하기 위해 부동산 가격 데이터도 같이 학습시켰다. 모델은 일조량과 타겟값인 부동산 가격 간의 관계를 추론하였는데, 이러한 방법이 지도학습이다.$^{**6}$

지도학습은 특정 카테고리를 분류하는 분류와 특정 수치를 예측하는 회귀 2가지로 구분할 수 있다. 위 부동산가격 예시는 부동산 가격이라는 연속적인 수치를 예측하는 테스크($T$) 이기 때문에 회귀(Regression) 이고 스팸 예시는 스팸인지, 스팸이 아닌지 2개의 카테고리를 분류하는 문제이기 때문에 분류(Classification)라고 한다.
지도학습을 아래와 같이 표현할 수 있다.
$y_{n}$이 예측하려는 타겟 레이블이고, $x_{n}$가 타겟값을 제외한 나머지 데이터일 때 지도학습에서 훈련데이터는 $(x_{i},y_{i})$ 를 원소로 갖는 집합으로 표현할 수 있다. 따라서 지도학습이란 $D={(x_{1},y_{1}),(x_{2},y_{2}),(x_{3},y_{3}),...,(x_{n-1},y_{n-1}),(x_{n},y_{n})} = {\displaystyle (x_{i},y_{i})^{N}_{i=1}}$를 훈련데이터(trainning data)로 갖는 모형을 지도학습이라 한다.
지도학습의 평가 ( $P$ )
지도학습의 목표는 그것이 회귀일지, 분류일지는 모르지만 학습된 데이터를 통해 학습하지 않은 데이터를 잘 예측하는것이다. 또한 사전이던 사후던 정답이 존재하기 때문에 모델의 예측결과가 잘 맞는지 평가할 수 있고, 지도학습은 평가한 결과($P$) 를 토대로 모델을 개선해나가는 프로세스를 따른다.
스팸 분류와 같은 분류(Classification)의 경우 정확도(Accuracy)(%) 를 사용하여 모델이 얼마나 잘 맞추는지 측정할 수 있고, 회귀(Regression)의 경우 평균 제곱근오차(RMSE)와 같이 예측한 값과 실제 값이 얼마나 차이가 나는지 등을 통해 모델의 정확도를 측정할 수 있다.
실제로 모델평가(Evaluation)과정은 각 데이터의 특성과 테스크의 특성에 따라서 정확도와 RMSE 외에도 여러 방법이 존재한다. 모델평가과정은 실제로 머신러닝 프로세스에서 굉장히 중요한 과정이고 잘못된 평가지표를 사용할 경우 의도와는 전혀 다른 모델이 만들어질지도 모른다.
예를 들어 훈련데이터 100개중에 90개가 일반메일이고 10개만 스팸이라고 해보자, 정확도를 사용할 경우 찍어도 산술적으로 90%의 정확도를 갖는다. 이렇게 불균형된 데이터에서는 정확도를 사용하지는 않고 F1 Score를 사용한다.
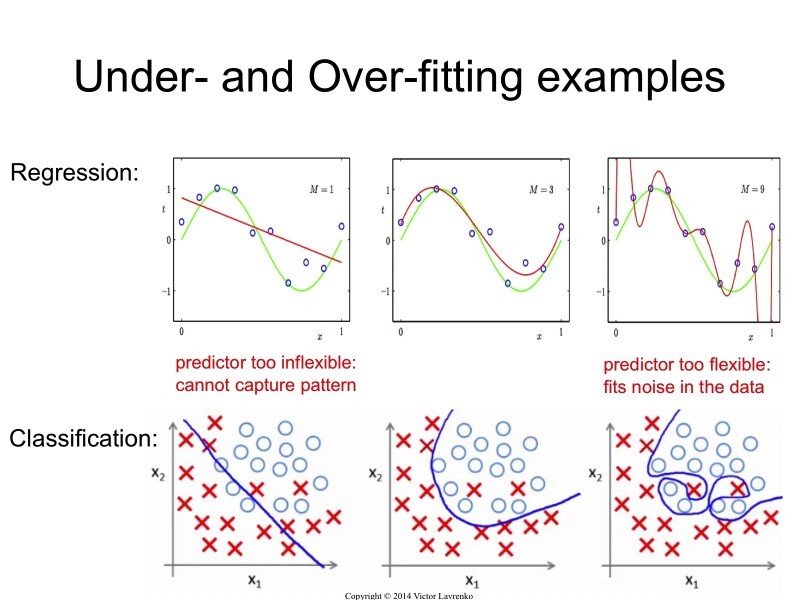
결국 머신러닝이란것이 훈련데이터로 추정한 $\hat f(x)$ 을 활용하기 때문에 모집단을 표현하는 모델 $f(x)$ 와는 차이가 발생할 수밖에 없다. 결국 모집단의 모델은 $f(x)=\hat f(x) + \epsilon , \ (\epsilon : error)$ 으로 표현할 수 있는데, $\epsilon$ 은 과적합(Overfitting)과 과소적합(Underfitting)으로 나눌 수 있다.
과적합(Overfitting)과 과소적합(Underfitting)
과적합(Overfitting)이란 훈련데이터에 지나치게 적합(fit) 된 모형을 말한다. 즉 훈련데이터에 지나치게 딱 맞아 떨어지는 바람에 훈련데이터에서는 높은 성능을 보이나, 실제 데이터의 예측 때는 오히려 성능이 낮아지는 문제를 말한다. 반대로 과소적합(Underfitting)의 경우 학습 데이터 재대로 학습하지 못하고 예측또한 성능이 좋지않은 케이스를 말한다.
이 둘은 하나가 늘어나면 하나가 줄어드는 이율배반적(Trade-off)관계이다. 과유불급이라고 너무 훈련데이터에 적합되는 과적합 상태도 좋지 않고, 과소적합되는 상태도 좋지 않다. 하지만 절대적인 균형상태가 무엇인가는 진행하는 프로젝트, 모델, 데이터에 따라 천차만별이다. 그 균형의 경우 정확하게 설계된 평가방법의 평가결과($P$)가 자연스럽게 높아질 것이고, 실제 예측도 잘할 것이다.
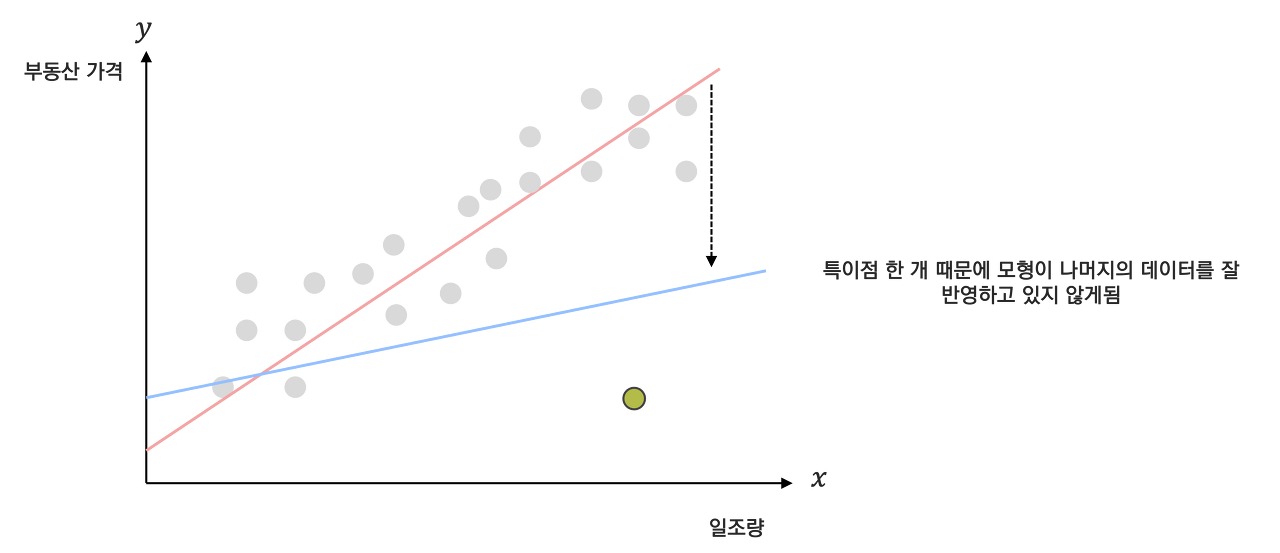
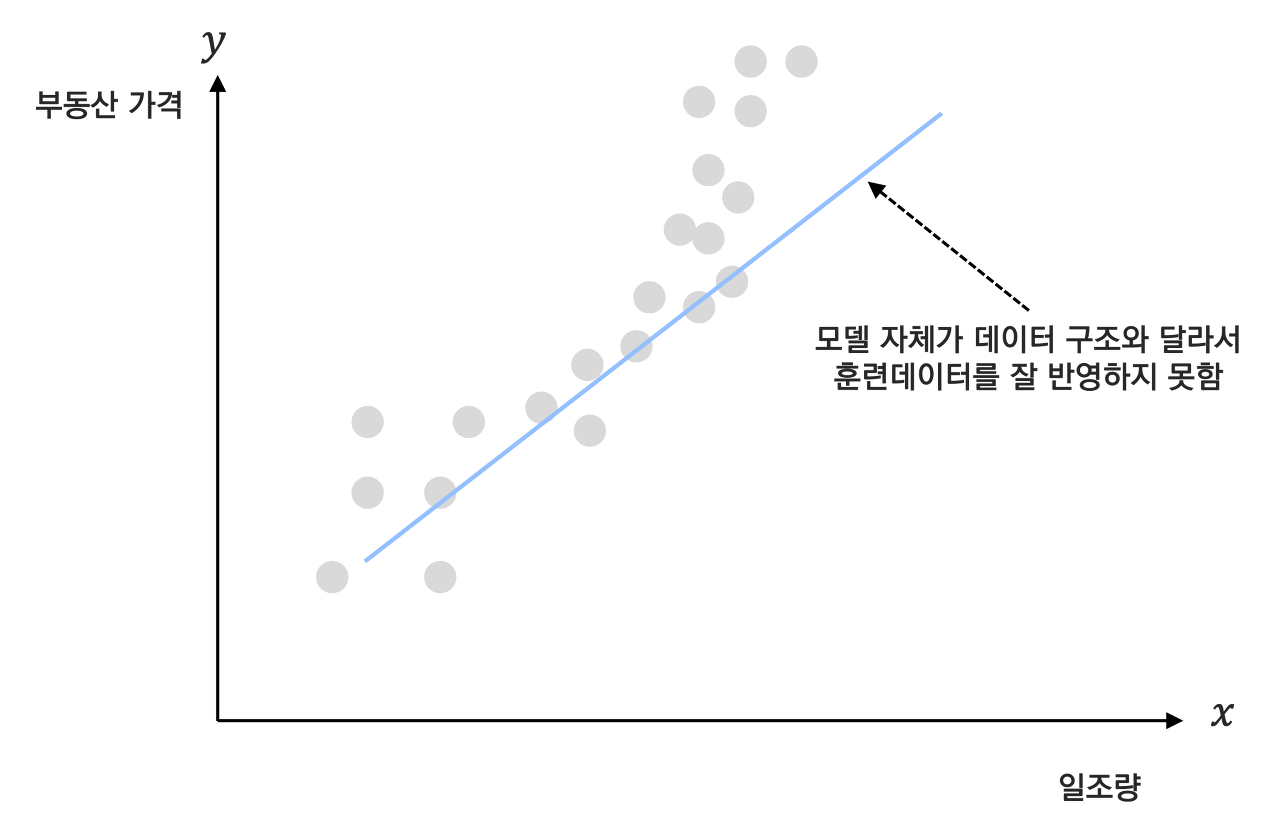
부동산 데이터에서 아래와 같이 혼자 동떨어진 데이터가 있을 경우를 한번 살펴보자
만약 특이점까지 모두 반영해버린 주황색선을 $\hat f(x)$ 로 할 경우 새로운 일조량이 들어왔을 때 예측을 잘 하지 못하는 모델일 것임을 쉽게 예상해볼만 한다. 따라서 해당 점을 엔지니어가 제거하거나, 추가적인 데이터를 학습시키는 등 붉은색 특이점이 모델에 미치는 영향을 최소화할 수 있도록 $\hat f(x)$를 조정해야한다.
반면에 과소적합(Underfitting)의 경우 모델이 데이터를 너무 반영하지 않았거나, 데이터에 맞지 않는 모형을 사용할 경우 발생하며, 훈련과정 자체에서 데이터의 반영이 잘 이루어지지 않은 것이다. 이 경우 모형의 알고리즘 자체를 변경하거나, 조금더 모델의 유연함을 늘리는 바향으로 해결한다.
비지도학습
비지도학습은 대규모 데이터 집합에서 의미 있거나 흥미로운 패턴을 찾는 $T$ 를 해결하기 위해 데이터($E$)를 활용하는 알고리즘을 말한다. 지도학습의 경우 예측을 위해 정답이 존재하는 데이터를 학습에 활용한 것과 달리 비지도학습은 단지 주어진 학습 데이터($E$) 속에서 특정 패턴을 추출하는 것을 목적으로 하기에, Knowledge Discovery 라고도 한다.
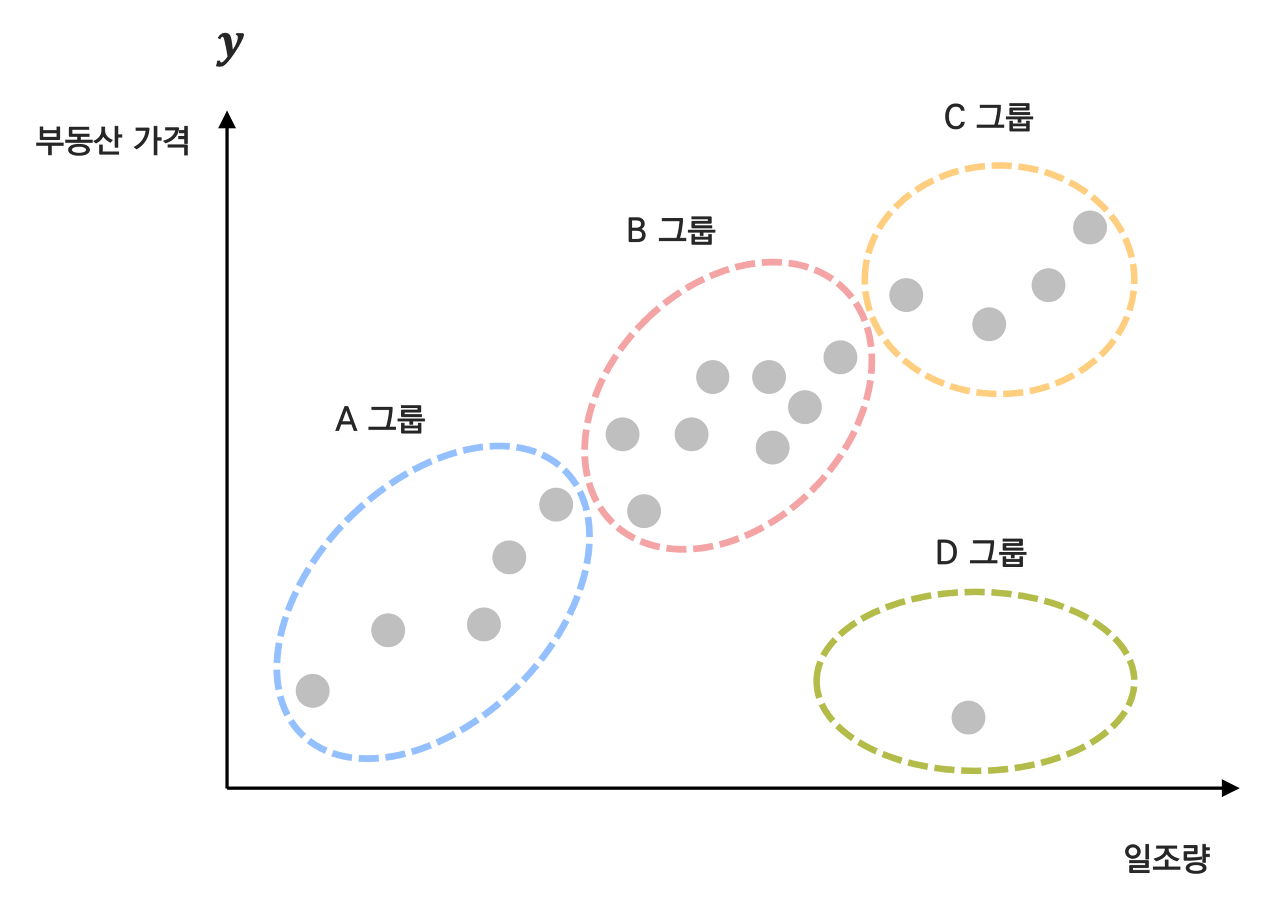
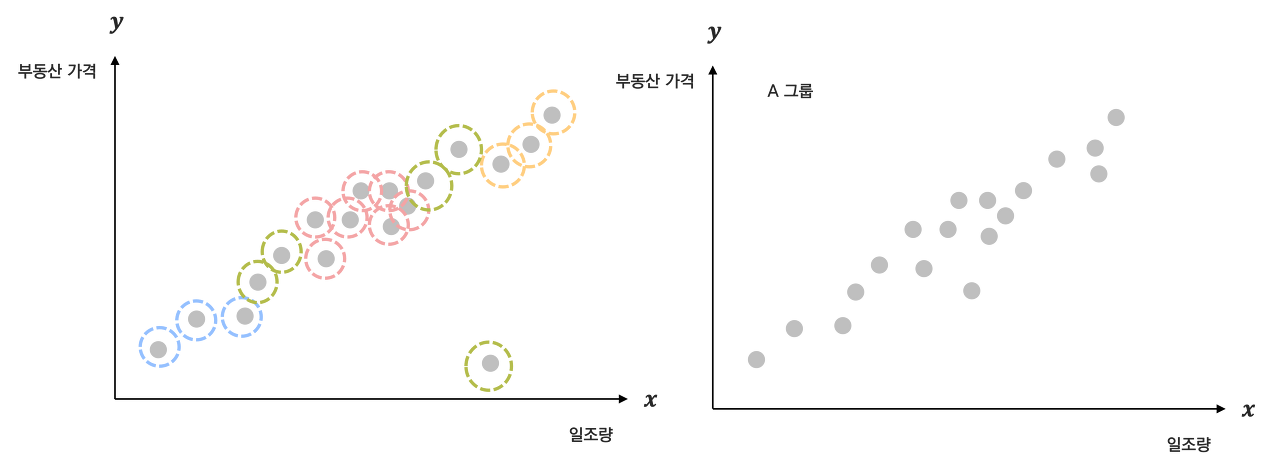
같은 부동산 데이터를 사용하더라도 비지도학습 알고리즘으로 데이터를 학습한다면, 아래와 같이 일조량과 부동산가격간의 관계에 따라 패턴에 따라 특정 패턴을 찾아보는 테스크($T$) 로 바꿔볼 수 도 있다.
일반적으로 학습데이터로 주어진 데이터를 특정 갯수의 그룹으로 나누는 군집(Clustering)이나, Representative Learning 이 대표적으로 비지도학습에서 많이 사용되곤 한다.
💡 비지도학습에서 훈련데이터는 $(x_{i})$ 를 원소로 갖는 집합으로 표현할 수 있다. 따라서 지도학습이란 $D={(x_{1}),(x_{2}),(x_{3}),...,(x_{n-1}),(x_{n})} = {\displaystyle (x_{i})^{N}_{i=1}}$를 훈련데이터(trainning data)로 갖는 모형을 지도학습이라 한다.
비지도학습의 평가
비지도학습은 패턴을 찾는 것이 목표이이고, 타겟값이 주어지지 않기 때문에 지도학습 처럼 정량적인 평가 지표($P$)를 얻을 수 없다. 따라서 일반적으로는 수행하려는 테스크를 잘 수행하고 있는지 주로 시각화나 별도 지표를 사용자가 생성하여 직관적으로 평가하곤 한다. 비지도 학습 역시 과적합(Overfitting)과 과소적합(Underfitting)의 문제가 존재한다.
예를 들어, 클러스터링을 수행할 때 클러스터의 개수를 결정하는데, 이 때 클러스터의 개수를 지나치게 늘리면 군집이 지나치게 작아져서 노이즈까지 클러스터링이 되는 문제가 발생할 수 있습니다. 또는 반대로 클러스터의 개수를 지나치게 줄이면 서로 다른 클러스터가 하나의 클러스터로 묶이는 문제가 발생할 수 있다. 따라서 군집수를 적당하게 조정하거나, 노이즈를 반영하지 않도록 하여 해결할 수 있다.
5. 머신러닝 프로세스
머신러닝은 1. 프로젝트 기획 → 2. 데이터 탐색 및 전처리 → 3. 머신러닝 알고리즘 선택 → 4. 머신러닝 모델 학습 → 5. 모델 평가 → 6. 모델 개선 → 7. 배포 과정을 계속 반복한다.
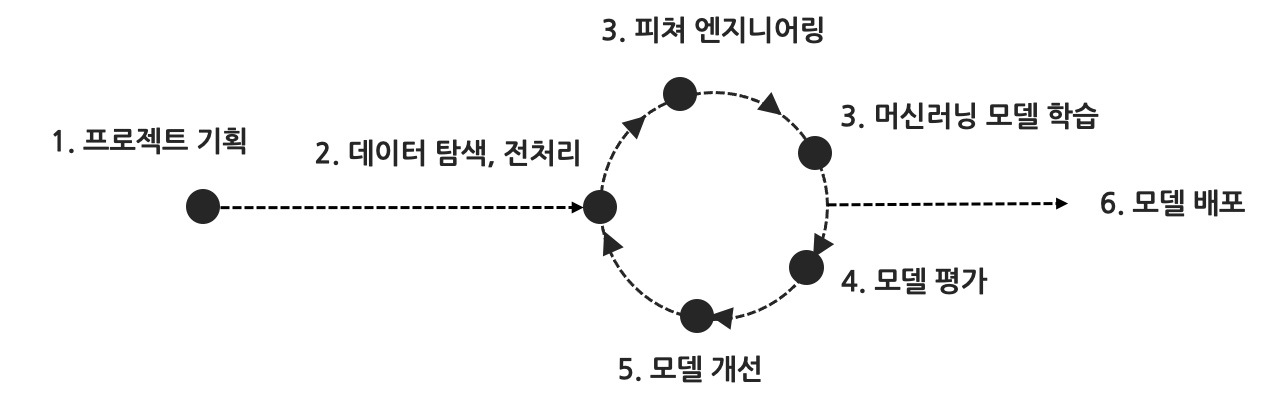
이 과정은 실제 알고리즘을 학습하고 배우는 단계에서 자연스럽게 녹여낼 예정이므로 지금은 간단하게 이해하고 넘어가도 좋다.
- 프로젝트 정의 :
- 머신러닝으로 해결할 테스크($T$)를 정의하고 학습을 평가할 평가지표($P$) 부터 머신러닝 알고리즘을 대략적으로 설계하는 단계이다.
- 예를 들어 스팸메일을 필터링하는 프로젝트를 진행할 경우 "스팸메일을 분류하는 머신러닝 개발" 이라는 테스크 $T$ 를 정의하고 "스팸메일" 인지 "일반메일" 인지 분류(Classification) 모델로 지도학습방법 분류 알고리즘을 사용, 평가방법 $P$ 는 정확도($Accuracy)$를 사용 등으로 테스크 $T$를 구체화한다. 이후 어떤 데이터를 학습모형에 활용할지 정의 한다
- 데이터 탐색, 전처리 :
- 이 과정에서는 실제 데이터를 탐색하여 데이터를 이해하고, 학습모형에 활용할 수 있도록 데이터를 전처리하는 과정이다.이 부분은 데이터마다, 테스크마다 다양한 작업이 이루어진다.
- 피쳐 엔지니어링:
- 피쳐 엔지니어링은 탐색하고 전처리한 데이터를 기반으로 모델에 사용할 피쳐를 선택하고, 파생변수를 만드는 등의 작업을 진행한다.
- 머신러닝 모델 학습 → 5. 모델 평가 → 6. 모델개선
- 3번에서 정의한 피쳐를 실제 모델에 학습하여, 결과를 측정하고 이를 기반으로 모델개선 작업을 진행한다. 이 때, 모델개선을 위해 2번 데이터 탐색과 전처리 혹은 3번 피쳐 엔지니어링으로 돌아가 배포를 위한 정확도를 얻을 때 까지 반복한다.
- 모델 배포 :
- 최종적으로 2-6번 과정을 반목하며 검증한 모델을 실제 프로덕션 레벨에 적용한다. 이 단계에서는 모델을 배포하고, 실제 데이터를 입력하여 예측을 수행하는 등의 작업이 이루어지며, 이 단계 이후로도 꾸준히 모델의 성능을 높이기 위한 작업은 지속된다.
미주
1 : 이해를 돕기위해서 극단적인 예시를 들었을 뿐, 실제로는 그 둘의 차이를 이해하고 이를 알고리즘에 녹여내는 것이 굉장히 중요한 작업이다. (따라서 데이터과학에 도메인 전문성이 굉장히 중요하게 취급된다.) 단, 여기서도 도메인 지식을 적용해서 컴퓨터가 데이터속에서 패턴을 잘 발굴할 수 있도록하는데 목표가 있다.
2 : Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 3rd Edition(2022), Aurélien Géron, O'Reilly Media, Inc. 의 Why Use Machine Learning?을 참고하여 재구성.
3 Machine learning an algorithmic perspective(2009, Stephen Marsland ,A CHAMPION & HALL BOOK) 의 Chapter 1. Introduction의 1.2 Learn을 참고하여 인간의 학습방법과 빗대어 설명하는 부분을 재구성함.
인용
[1] Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 3rd Edition(2022), Aurélien Géron, O'Reilly Media, Inc.
“ The field of study that gives computers the ability to learn without being explicitly programmed.”(Arthur Samuel, 1959)
[2] : Deep Learning(2016), Ian Goodfellow and Yoshua Bengio and Aaron Courville, An MIT Press book, 97p
“ A machine learning algorithm is an algorithm that is able to learn from data ”
[3] : Deep Learning(2016), Ian Goodfellow and Yoshua Bengio and Aaron Courville, An MIT Press book, 97p
” A computer program is said to learn from experience $E$ with respect to some class of tasks $T$ and performance measure $P$ , if its performance at tasks in $T$ , as measured by $P$ , improves with experience $E$ ”
[4] 수학적 모델링의 이해(황혜정,2007).학교수학,9(1),65-97.
논문내 내용을 요약하여 재구성 하였음.
참고문헌
- 도서
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 3rd Edition(2022), Aurélien Géron, O'Reilly Media, Inc.
- Deep Learning(2016), Ian Goodfellow and Yoshua Bengio and Aaron Courville, An MIT Press book
- 처음 배우는 머신러닝: 기초부터 모델링, 실전 예제, 문제 해결까지(2017), 김승연, 정용주, 한빛미디어
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 3rd Edition(2022), Aurélien Géron, O'Reilly Media, Inc.
- 논문
- 황혜정.(2007).수학적 모델링의 이해.학교수학,9(1),65-97.
'분석이론 > 기계학습(Machine Learning)' 카테고리의 다른 글
| [실용적 머신러닝 시리즈] 들어가며 (Introduction) (0) | 2023.03.05 |
|---|

댓글